- PS_PAY_CHECK
- PS_PAY_DEDUCTION
- PS_PAY_EARNINGS
- PS_PAY_OTH_EARNS
- PS_PAY_TAX
Payroll Aggregate Star Schema

In order to load the W_PAYROLL_A table at a different time grain, you must set the GRAIN parameter in DAC (Data Warehouse Administration Console). Out of the box, the parameter is set to MONTH but other possible values are DAY, WEEK, QUARTER, and YEAR. Your business requirements and report performance will determine the proper setting for this parameter. To change the GRAIN parameter follow these steps:
1. In DAC, go to the Design view, and select a container
2. From the Tasks tab, find the task named PLP_PayrollAggregate_Load.
3. Display the Parameters subtab, and add a parameter with the name $$GRAIN.
4. Define the value as one of the following: 'DAY', 'WEEK', 'MONTH', 'QUARTER' or 'YEAR'.
5. Select Static as the parameter type.
6. Save the task.
W_PAYROLL_A is loaded from the base table W_PAYROLL_F in the initial full load ETL run by the workflow PLP_PayrollAggregate_Load_Full. On subsequent incremental runs, the aggregate table is not rebuilt but is instead updated by adding new records or applying changed rows to the existing aggregate rows.
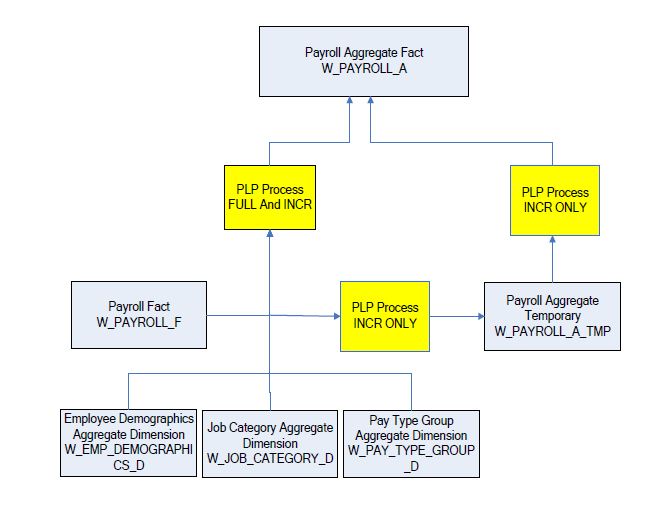
The incremental process is done in two steps:
1. There are new records in the W_PAYROLL_F table, which were inserted since the last ETL load. The new records are inserted into the W_PAYROLL_A_TMP table. This step is part of the post oad-processing workflow, and the mapping is called 'PLP_PayrollAggregate_Extract'.
2. The W_PAYROLL_A_TMP table is processed by joining it with the W_PAYROLL_A aggregate table to insert new or update existing rows to the aggregate table. This step is part of the post load-processing workflow, and the mapping is called 'PLP_PayrollAggregate_Load'. The incremental refresh process is based on the fact that there are typically no updates to the existing fact rows, just new rows that may reverse or adjust other payroll data. Using the ITEM_AMT column from W_PAYROLL_F, the existing aggregate row is updated by adding that amount to the current aggregate amount.
Aggregate ITEM_AMT = Old ITEM_AMT (from W_PAYROLL_A) + New ITEM_AMT (from W_PAYROLL_A_TMP)
No comments:
Post a Comment